
为了搞清楚人类是怎么看世界的,计算机开始学着“转动眼球”了:
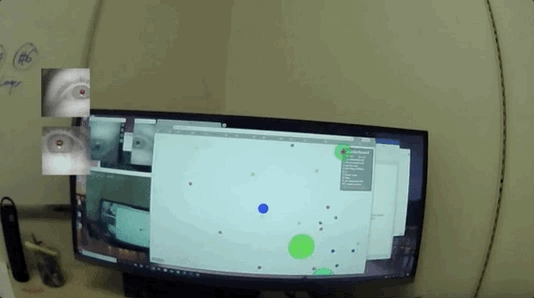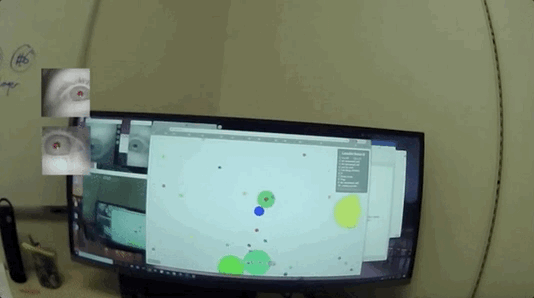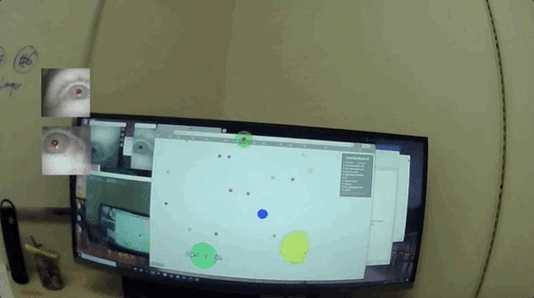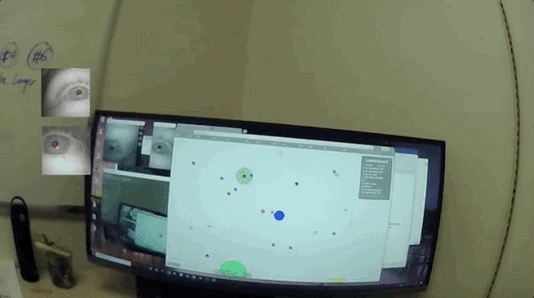
然后凭借转动的眼球“搜集要观测的信息”,再聚焦在文字或者图像上,开始“收集数据”:
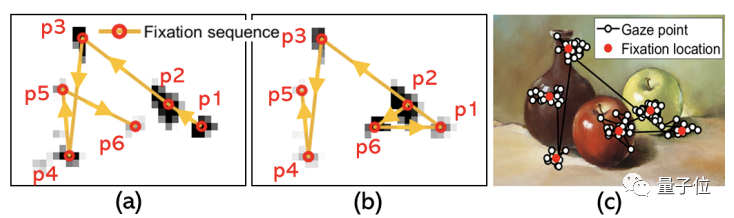
不仅能正常读书看画,甚至能模拟人类在无聊、兴奋、紧张等各种不同情绪下的瞳孔放缩、眨眼频率的细微变化。

事实上,这是杜克大学的研究人员最新开发的一种“虚拟眼睛”,可以精确模拟人类观测世界的方式。这项研究目前已经开源,并即将发表于通信类顶会 IPSN 2022 上。
通过这项研究得到的几近真实的数据,将全部反哺给计算机。
这些数据有什么用?
这种基于眼球追踪(Eye Tracking)技术得到的数据常常被称为眼动数据,包括注视时长、眼跳、追随运动等多个属性。
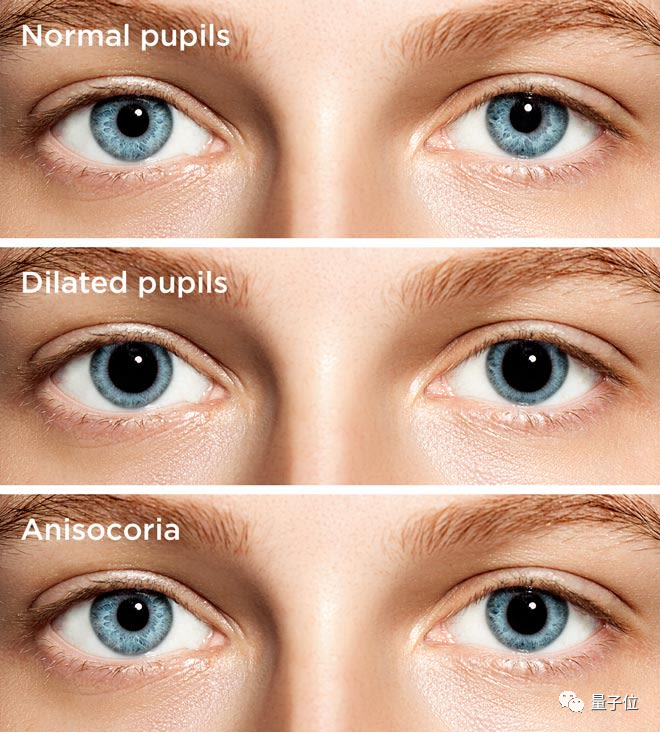
就如我们常常将眼睛成为心灵之窗一样,这些眼动数据能反映不少人类的真实信息。比如,瞳孔的扩张、眼跳、游移次数可以表现当前主人的情绪(无聊或兴奋)、注意力是否集中、对某项任务是新手或娴熟、甚至是对某种特定语言的精通与否。
这项研究的作者之一 Maria Gorlatova 甚至表示:
(眼动数据)可能无意中暴露出性别和种族偏见、我们不想让别人知道的兴趣,甚至我们自己都不了解的信息。
因此,对这些眼动数据的学习和研究,自然也就能产生一系列传感应用:包括认知负荷估计、久坐活动识别、阅读理解分析和情感识别。很多企业和开发者,比如微软的 VIVE Pro Eye,已经开始采用眼球追踪来实现基于目光的新的交互和环境感知。
然而,在收集大规模的、有标签的眼动数据时,难免会碰到几个问题:
人类视觉行为的随机性增加了数据收集的成本
与人类受试者合作过程中可能涉及隐私侵犯问题
生产模型训练所需的数据的时间成本过高(可能需要数以百计的人带着设备不间断地用眼数小时才能产生)
虚拟眼睛收集数据
如何解决上面的问题呢?杜克大学的研究团队提出了一套受心理学启发的模型 EyeSyn。这一模型只利用公开的图像和视频,就能合成任意规模大小的眼动数据集。它的整体架构如下:
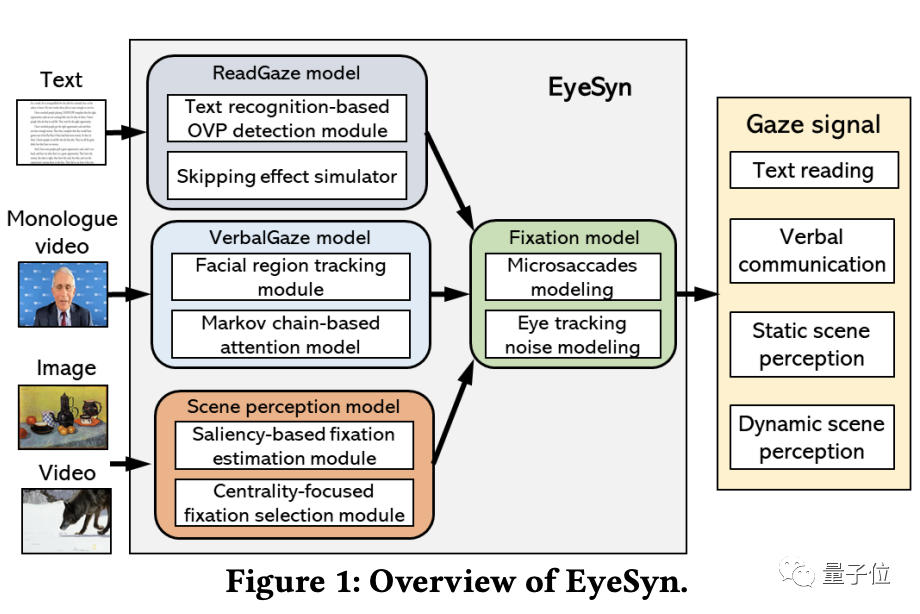
整体思路是以图像和视频作为输入,并将其作为视觉刺激,以生成相应的眼动数据。
大的架构又由三个小模型组成:
ReadGaze 模型
模拟文本阅读中的视觉行为。拥有一个基于文本识别的检测模块、一个模拟跳读视觉行为的模拟器。
VerbalGaze 模型
模拟在口头交流中固定在面部某个区域、以及在面部不同区域之间切换注意力的视觉行为。拥有一个面部区域跟踪模块、一个基于马尔可夫链的注意力模型(Markov Chain-based Attention Model)。
StaticScene 和 DynamicScene 模型
模拟感知静态和动态场景过程中的眼球运动。拥有一个基于图像特征的显著性检测(Saliency Detection)模型,用以识别视觉场景中潜在的定点位置。
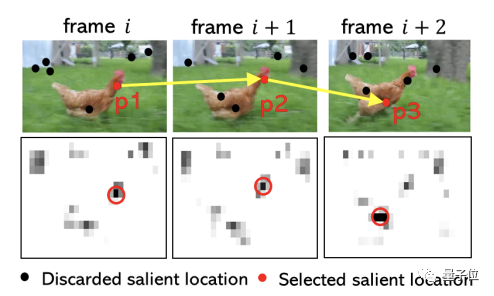
△动态场景中的眼动数据
基于这些构成,EyeSyn 不需要基于已有的眼动数据进行训练,上岗就能直接开始工作。
并且,与传统眼动数据的收集过程相比,EyeSyn 在模拟不同的眼动跟踪设置、视觉距离、视觉刺激的渲染尺寸、采样频率和受试者多样性上,也更加方便快速。
现在,只基于一小部分图像和视频,EyeSyn 就可以合成超过 180 小时的眼动数据,比现有的基于目光的活动数据集大 18 到 45 倍:

研究人员 Maria Gorlatova 表示,“合成数据本身并不完美,但这是一个很好的起点。”
小公司不用再花费过多的时间和金钱与人类受试者合作,建立真实活动数据集,而是可以直接使用这种方法。
这种更加快速的眼动数据的生产方式,将使得普通的 VR、AR、还有元宇宙平台中的相关应用程序的制作都更加便捷。

△Maria Gorlatova
论文:
https://www.researchgate.net/publication/359050928_EyeSyn_Psychology-inspired_Eye_Movement_Synthesis_for_Gaze-based_Activity_Recognition
开源链接:
https://github.com/EyeSyn/EyeSynResource
参考链接:
https://techxplore.com/news/2022-03-simulated-human-eye-movement-aims.html
